Nov 2020 - Mar 2022
Visually Guided Machine Learning with Ex Machina
Summary
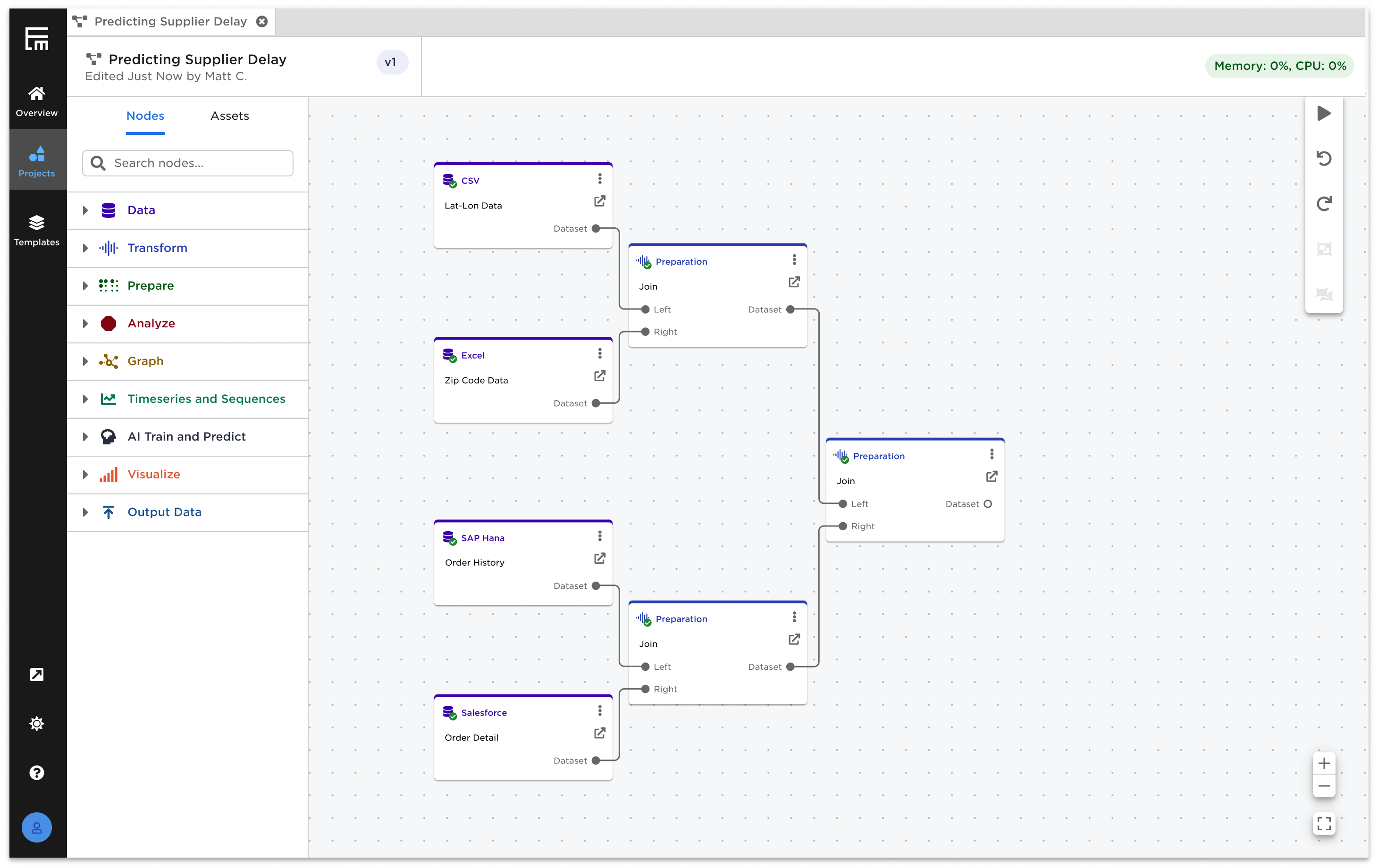
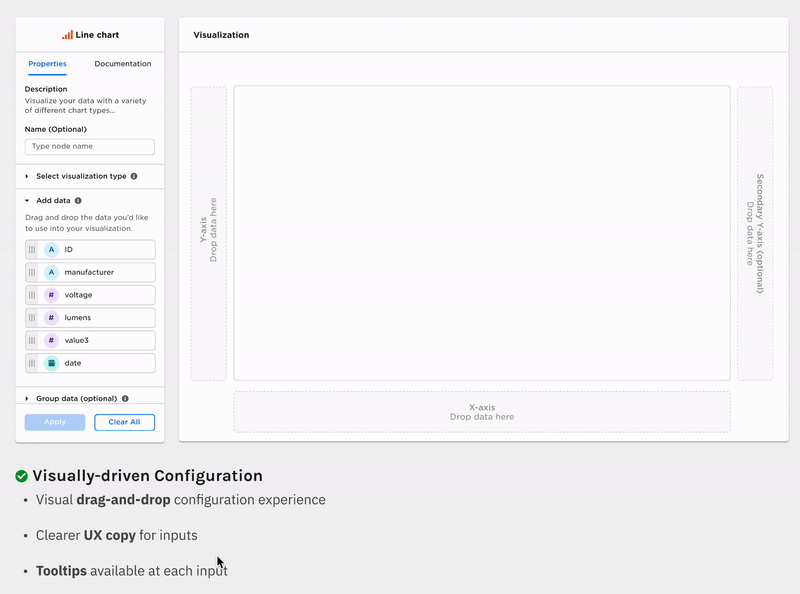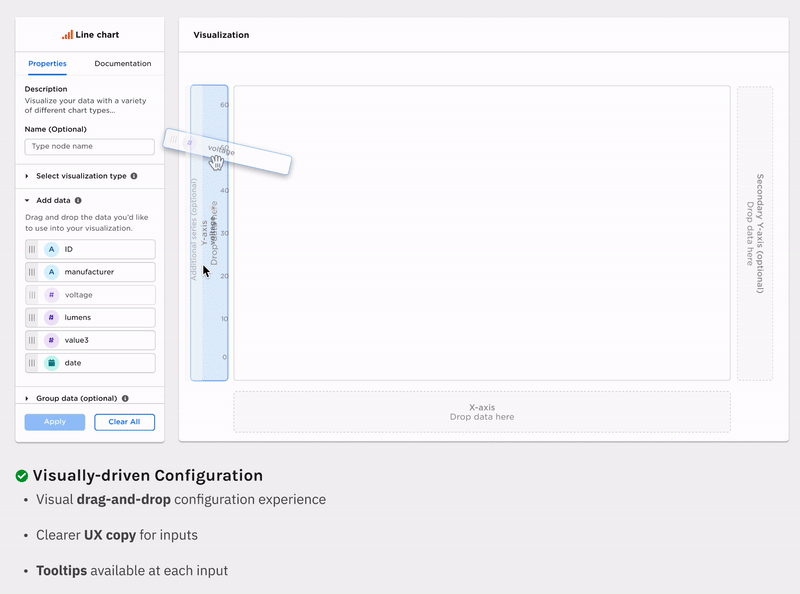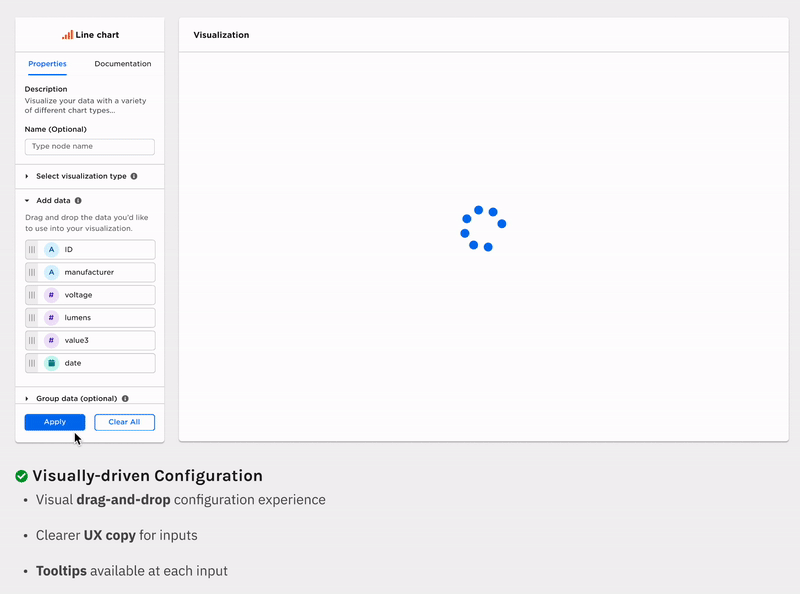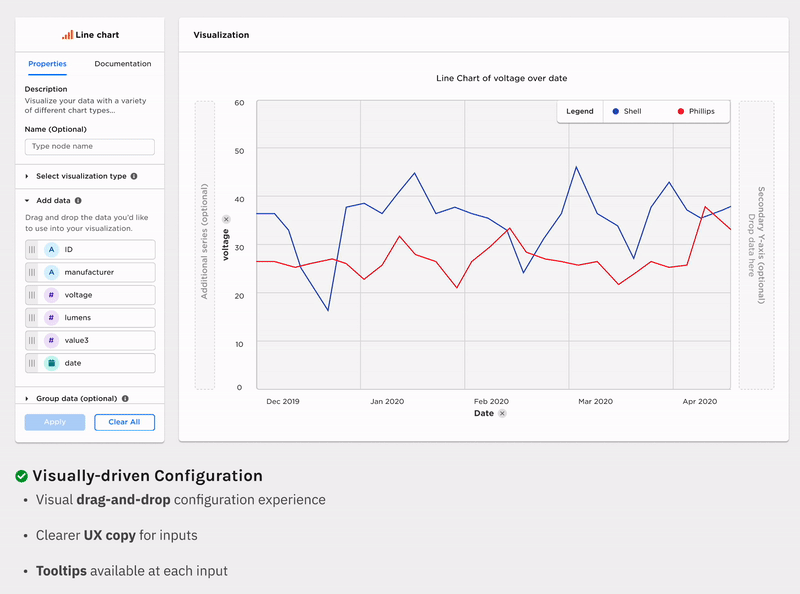
Ex Machina is a low-code data exploration and analytics tool for non-technical users (Data Analyst, Business Analyst, Strategy Associate, etc). Its primary goal is to help businesses with limited technical resources/expertise to understand their data and leverage lightweight machine learning functionality in a visually guided way.
Collaborators
Josh P. (Project Manager), Matt Connor (Project Manager), Lisa Xu (Designer)
Role and Responsibilities
Research and Design Lead
Primary and Secondary Research, User/Usability Testing, Heuristic Analysis, Affinity Diagramming, Concept Mapping, Low to high fidelity Design